



ردیس (Redis) چیست؟ آشنایی با ویژگیها، کاربردها و مزایای ردیس
در حوزه مدیریت و تحلیل داده، ردیس (Redis) به عنوان یک ابزار همهکاره و قدرتمند شناخته میشود که توجه دِوِلوپرها و حرفهایهای وب را در سراسر جهان به خود جلب میکند. ویژگیهای قابل توجه Redis، از جمله عملکرد بالا، ذخیرهسازی دادهها در حافظه و پشتیبانی از ساختارهای مختلف داده، آن را در خط مقدم برنامههای کاربردی مدرن قرار داده است. ردیس یک پایگاه داده NoSql بسیار قدرتمند است که کمک میکند برنامههایی که کاربران زیادی دارند در سمت سرور سرعت بالاتری داشته باشند. Redis علاوه بر رایگان بودن، یک ابزار پرکاربرد برای ذخیره و بازیابی اطلاعات است.
فرقی نمیکند اگر یک دِوِلوپر باتجربه هستید یا یک تازهواردِ کنجکاو، این بلاگ، هرآنچه که درباره Redis باید بدانید و کاربردهای عملی آن را روشن میکند. در این بلاگ با ما همراه باشید تا کشف کنید که چگونه Redis می تواند فرآیندهای مدیریت داده شما را متحول کند و کارایی برنامههای شما را افزایش دهد.
رِدیس (Redis) چیست؟
ردیس (به انگلیسی: Redis) مخفف Remote Dictionary Server مانند یک سیستم ذخیره سازی برای داده های شما است، اما با پیچ و تاب بیشتر! Redis یک سیستم متن باز برای ذخیرهسازی داده است که بر اساس کلید-مقدار (key-Value) NoSQL دادهها را بر روی حافظه RAM ذخیره میکند. ردیس فوق العاده سریع است و می تواند انواع مختلفی از دادهها را مدیریت کند. ردیس مانند یک قفسه کتاب سوپرشارژ است که می توانید اطلاعات خود را در آن ذخیره کنید و هر زمان که به آن نیاز داشتید به سرعت به آن دسترسی پیدا کنید. از Redis میتوان به عنوان پایگاه داده (Database)، حافظه کش (Cach memory)، سرور پخش ویدئو (Video Streaming Server) و واسط پیام (Message Broker) استفاده کرد. از این رو، ردیس یک راه قدرتمند و کارآمد برای ذخیره و بازیابی دادهها در برنامههای شما است.
یکی از ویژگیهای ردیس که عمدتا برای آن شناخته شده است، سرعت بالای آن و قابلیت پشتیبانی آن از ۵۰ زبان برنامهنویسی مختلف است. از Redis برای صنایع، فناوریها و مواردی مانند صنعت بازی، فناوری Ad-Tech، سرویسهای مالی، اینترنت اشیاء و شبکههای اجتماعی استفاده کرد که که در آنها عامل زمان از اهمیت بسیاری بالایی برخوردار است.
ردیس برای سالهای متوالی در بین برنامهنویسان به دلیل عملکرد خوب و کابری آسان به عنوان محبوبترین پایگاه داده شناخته شده است. با این حال ردیس فاقد برخی از ویژگیهای پایگاههای داده سنتی مانند MySQL و MongoDB است. از این رو، قبل از استفاده از ردیس باید با نیازهای وبسایت یا اپلیکیشن خود و همچنین تمام ویژگیها و مزایا و معایب ردیس آشنا شوید.
امروزه شرکتهای مختلفی از ردیس استفاده میکنند که از میان مهمترین آنها میتوان به توئیتر (ایکس)، اوبر و پینترست اشاره کرد که این موضوع نشاندهنده قدرت و محبوبیت بالای این سیستم ذخیرهسازی حرفهای است.
توضیح تخصصی ردیس بر اساس این مطلب از Redis به شرح زیر است:
ردیس (Redis) یک Open source (منبع باز) مجوز گرفته از BSD است که از آن برای محل ذخیره داده در حافظه به عنوانهای زیر استفاده میشود:
- دیتابیس (Database)
- کَش (Cach)
- واسط پیام (Message broker)
- موتور جریان (Streaming engine)

انواع داده ردیس
در این بخش با انواع دادههای ردیس آشنا خواهیم شد.
رشتهها (Strings)
رشته ها اساسی ترین نوع داده در Redis هستند. آنها دنباله ای از بایت ها را نشان میدهند که می توانند متن، اشیاء سریالی یا حتی داده های باینری را در خود نگه دارند. استرینگهای Redis از نظر باینری ایمن هستند، به این معنی که می توانند هر نوع دادهای را بدون هیچ گونه رمزگذاری یا تبدیل ذخیره کنند. این تطبیق پذیری Stringها را برای طیف وسیعی از موارد استفاده، از جمله کش کردن، ذخیره تنظیمات برگزیده کاربر، و مدیریت جفت های کلید-مقدار ساده، ایده آل میکند.
هشها (Hashes)
هشهای Redis نوعی ساختار داده هستند که نگاشت کلیدها به مقادیر را ذخیره میکنند. آنها شبیه دیکشنریهای پایتون، جاوا HashMaps و هشهای روبی هستند. هش ها قابل تغییر هستند، به این معنی که می توان آنها را در هر زمانی به آن اضافه کرد، تغییر داد و حذف کرد. هشها همچنین برای بازیابی مقادیر فردی کارآمد هستند و آنها را برای ذخیره و بازیابی اشیاء پیچیده ایده آل میکند. هشها اغلب برای پیادهسازی شمارندهها و همچنین ذخیرهسازی و مدیریت جلسه استفاده میشوند. Hashها یک ساختار داده همه کاره هستند که می توانند برای طیف گسترده ای از وظایف در Redis استفاده شوند.
لیستها (Lists)
لیستهای Redis مجموعههای مرتب شدهای از رشتهها هستند، شبیه به لیستهای لینک شده. آنها برای قرار دادن و حذف عناصر در سر یا دم بهینه شده اند. لیستها همه کاره هستند و میتوانند برای کارهای مختلف از جمله اجرای stackها و queuesها، ساخت leaderboardsها و مدیریت تسکها و ایونتها استفاده شوند. لیستها همچنین عملکرد بسیار بالایی دارند، و برای ذخیره و بازیابی دادههایی که اغلب به آنها دسترسی دارید ایده آل هستند.
سِتها (Sets)
Set های Redis مجموعهای نامرتب از رشتههای منحصربهفرد هستند، شبیه مجموعههایی در زبانهای برنامهنویسی مانند جاوا و پایتون. آنها برای ذخیره و بازیابی کارآمد آیتمهای متمایز طراحی شدهاند، و آنها را برای کارهایی مانند ردیابی شناسههای منحصر به فرد کاربر، فیلتر کردن ورودی های تکراری و انجام عملیات مجموعهای مانند Intersection ها، union ها و difference ها ایده آل میکند. مجموعهها در Redis عملکرد بالایی دارند، زیرا عملیاتهایی مانند افزودن، حذف، و بررسی عضویت را میتوان بدون در نظر گرفتن تعداد عناصر در زمان ثابتی اجرا کرد. این باعث می شود آنها برای برنامههایی که نیاز به دسترسی سریع به دادههای منحصر به فرد دارند مناسب باشند.
سِتهای مرتبشده با کوئریهای مختلف (Sorted sets with range queries)
در Redis، سِتهای مرتب شده یک نوع داده است که ویژگیهای Set ها و Set های مرتب شده را ترکیب میکند. مشابه Set ها، Set های مرتب شده اعضای منحصر به فرد را ذخیره میکنند، اما برخلاف Set ها، هر عضو با یک امتیاز همراه است. این امتیاز به هر عضو یک مقدار عددی اختصاص میدهد و به آنها اجازه میدهد از پایینترین به بالاترین امتیاز مرتب شوند. کوئریهای محدوده در Redis به شما امکان میدهد طیف خاصی از اعضا را از یک مجموعه مرتبشده بر اساس امتیازات آنها بازیابی کنید. این قابلیت صفحهبندی و رتبه بندی کارآمد را ممکن میکند و سِتهای مرتبشده را برای برنامههایی مانند تابلوهای امتیازات، تجزیه و تحلیل real-time و زمانبندی کاری بسیار موثر میکند.
بیت مپها (Bitmaps)
Bitmapهای Redis یک ساختار داده ای هستند که امکان ذخیره سازی کارآمد و دستکاری مجموعههای بزرگی از داده های باینری را فراهم میکند. به جای استفاده از یک ساختار داده بیت مپ واقعی، Bitmap های ردیس از نوع داده String برای نمایش یک آرایه بیت استفاده میکنند. این رویکرد Redis را قادر میسازد تا حداکثر ۲^۳۲ بیت داده را ذخیره کند که به معنای حجم عظیم ۵۱۲ مگابایت داده باینری است. بیت مپهای ردیس در مدیریت مجموعه دادههای بزرگ بدون مصرف حافظه بیش از حد عالی هستند، و به ویژه برای برنامههایی که نیاز به دسترسی سریع به اطلاعات boolean دارند، مفید هستند. به عنوان مثال، Bitmap های ردیس میتوانند به طور موثر user permissions، game maps، یا set memberships را نشان دهند.
هایپرلاگها (Hyperloglogs)
HyperLogLogs یک ساختار داده احتمالی (probabilistic) در Redis است که برای تخمین اصلی بودن یا تعداد عناصر منحصر به فرد در مجموعه بزرگی از دادهها استفاده میشود. برخلاف ساختارهای داده مجموعه سنتی، HyperLogLogs به طور موثر با معامله دقت کامل برای صرفه جویی قابل توجه در حافظه به این امر دست می یابد. آنها با استفاده از روش نمونهگیری به این امر دست مییابند که به آنها اجازه میدهد با استفاده از حداکثر ۱۲ کیلوبایت حافظه، کاردینالیته را با خطای استاندارد تنها ۰.۸۱ درصد تخمین بزنند. این آنها را برای موقعیتهایی ایدهآل میکند که در آن تعداد تقریبی اصلی کافی است، مانند شمارش تعداد بازدیدکنندگان منحصر به فرد یک وبسایت یا تعداد کلمات کلیدی مختلف مورد استفاده در سرچ کوئریها.
فهرستهای مکانی (Geospatial Indexes)
Geospatial Indexes در Redis یک ویژگی قدرتمند است که به شما امکان میدهد به طور کارآمد دادههای جغرافیایی را ذخیره و کوئری کنید. فهرستهای مکانی شما را قادر میسازند تا به سرعت نقاط را پیدا کنید، مکان های نزدیک را شناسایی کنید و تجزیه و تحلیل های فضایی پیچیده را انجام دهید. Redis از تکنیکی به نام Geohash برای رمزگذاری مختصات به String های فشرده استفاده میکند که امکان جستجوی کارآمد محدوده و نزدیکی را فراهم میکند. این باعث میشود فهرستهای مکانی برای برنامههایی مانند نقشهبرداری، ناوبری، تدارکات و خدمات مبتنی بر مکان ایدهآل باشند.
استریمها (Streams)
Redis Streams یک ساختار داده قدرتمند است که در Redis 5.0 معرفی شده است. استریمها طراحی شدهاند تا Data stream های با توان عملیاتی بالا را مدیریت کنند و برنامهها را قادر میسازند تا حجم زیادی از رویدادها را به طور موثر مدیریت و پردازش کنند. Streamها ترکیبی منحصر به فرد از عملکرد append-only log با قابلیت های دسترسی تصادفی را ارائه میدهند که آنها را برای موارد مختلف از جمله منبع یابی ایونت، نظارت بر داده های حسگر و real-time alerting میکند.
Redis دارای تکثیر داخلی (built-in replication)، اسکریپتنویسی Lua، حذف LRU، تراکنشها و سطوح مختلف پایداری روی دیسک (on-disk persistence) است و از طریق Redis Sentinel و پارتیشنبندی خودکار با Redis Cluster دسترسی بالایی را فراهم میکند.
Redis همچنین شامل موارد زیر میشود:
- Transactions
- Pub/Sub
- Lua scripting
- Keys with a limited time-to-live
- LRU eviction of keys
- Automatic failover
شما می توانید از Redis از اکثر زبانهای برنامه نویسی استفاده کنید.
ردیس چگونه کار میکند؟
همانطور که پیشتر توضیح دادیم، ردیس (Redis) یک سیستم پایگاه داده است که بر اساس مدل in-memory عمل میکند. این به آن معناست که دادهها را در حافظهی سرور نگهداری میکند و دسترسی سریعتری را فراهم میکند. زمانی که برنامه شما درخواستی را برای دریافت یا ذخیره داده از Redis دارد، روند زیر را طی میکند:
۱. ابتدا Redis را از طریق این لینک و یا یکی از ابزارهای مدیریت پکیج لینوکس (apt ، yum و Brew) دریافت کرده و سپس بر روی سرور خود نصب و فعالسازی کنیم. (ردیس را میتوان بر روی سیستمعاملهای لینوکس (اوبونتو، کالی و …)، مکاواس و ویندوز نصب کرد اما با این حال نسخه ویندوز آن عملکرد چندان خوبی ندارد.)
۲. وقتی کاربری از طریق کلاینتی درخواستی را برای دریافت محتوای مورد نظر خود به سمت سرور ردیس میفرستد، برنامه یک درخواست به ردیس ارسال میکند و درخواست شامل یک کلید و عملیاتی مثل دریافت (GET) یا ذخیره (SET) میباشد.
۲. اگر ردیس داده مورد نظر را در حافظه داشته باشد، کاربر در حافظه RAM (کش هیت) آن را به سمت کلاینت میفرستد، پاسخ مستقیماً به برنامه ارسال میشود و مرحله به پایان میرسد.
۳. اگر ردیس داده را در حافظه نداشته باشد (کش میس)، ردیس به پایگاه دادهی دائمی (مانند دیتابیس رابطهای) میرود و کلاینت آن را از منبع اصلی (پایگاه داده و …) گرفته و برای استفاده در آینده در سرور Redis ذخیره میکند.
(ردیس یک سیستم کشینگ In-Memory است و در نتیجه به جای ذخیرهسازی دادهها بر روی هارد دیسک و یا SSD، آنها را بر روی حافظه RAM خود ذخیره میکند که این امر باعث کاهش لتنسی، افزایش سرعت تحویل محتوا به کلاینتها و همچنین کاهش فشار وارده بر سرورها و پایگاههای داده میشود.)
۴. در نهایت، ردیس پاسخ مربوطه را به برنامه ارسال میکند.
برای افزایش عملکرد، ردیس از تکنیکهای مانند کشسازی و نمایهسازی استفاده میکند. همچنین، امکانات دیگری مانند انتشار-اشتراک (Publish-Subscribe) و صفها (Queues) نیز در ردیس وجود دارد.
مراحل کار ردیس (ذخیرهسازی دادهها / دریافت دادهها)
حالت ذخیرهسازی دادهها

- ارسال درخواست به ردیس
کاربر از طریق کلاینت (مرورگر، اپلیکیشن، نرمافزار، سرویس آنلاین و …) با سرور ردیس ارتباط برقرار کرده و دستور Set یا Get را به همراه یک جفت کلید-مقدار به سمت آن ارسال میکند. کلیدها معمولا به شکل بوده و مقادیر نیز شامل دادههایی با فرمتهای مختلف (فهرست، مجموعه، هش و …) میشوند.
2. ذخیرهسازی دادهها
سرور موارد دریافتی را مورد پردازش قرار داده و در صورتی که جفت کلید-مقدار ارسالی موجود نباشد، آنها را در حافظه RAM خود ذخیره میکند. اگر هم دادهها از قبل در سرور موجود باشند، در این صورت ردیس آنها را بهروزرسانی میکند.
حالت دریافت دادهها
در حالت دریافت دادهها، دو سناریوی مختلف میتواند اتفاق بیافتد: کش هیت و کش میس.
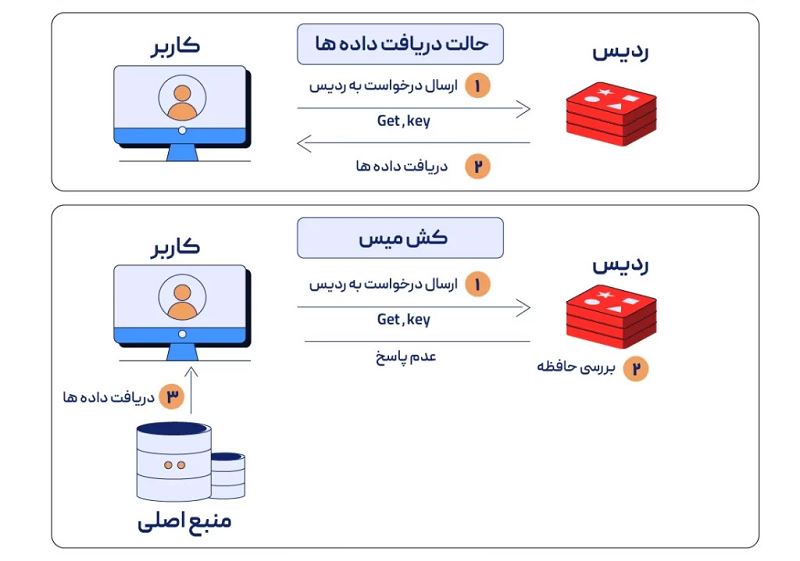
حالت کش هیت
- ارسال درخواست به ردیس
کاربر از طریق کلاینت خود با سرور ردیس ارتباط برقرار کرده و این بار دستور Get را به همراه کلیدی که به دادههای درخواستی مرتبط هستند، به سمت سرور ردیس ارسال میکند.
2. دریافت دادهها
سرور ردیس کلید دریافتی را با کلید موجود در حافظه RAM انطباق داده و پس از پیدا کردن دادههای مرتبط با کلید، آنها را به سمت کلاینت میفرستد.
حالت کش میس
- ارسال درخواست به ردیس
کاربر به مانند حالت کش هیت، درخواستی را به همراه یک کلید به سمت سرور میفرستد.
2. بررسی حافظه
سرور ردیس حافظه RAM را مورد بررسی قرار میدهد اما کلید ارسالی و در نتیجه دادههای درخواستی در آن موجود نیست.
3. دریافت دادهها از منبع اصلی
کلاینت به دلیل موجود نبودن دادهها در سرور ردیس، آنها را به صورت مستقیم از پایگاه داده دریافت کرده و به منظور استفاده در آینده در سرور ردیس ذخیره میکند.
تفاوت ردیس با پایگاه دادههای دیگر چیست؟
Redis از چندین جهت با پایگاه های داده سنتی متفاوت است. در اینجا برخی از تفاوت های کلیدی بین Redis و سایر پایگاه های داده وجود دارد:
مدل داده
Redis در درجه اول یک فضای ذخیرهسازی کلید-مقدار است، به این معنی که دادهها را به صورت جفت کلید-مقدار ذخیره میکند. همچنین، از انواع مختلف داده از جمله رشتهها (strings)، لیستها (lists)، مجموعهها (sets)، مجموعه های مرتب شده (sorted sets)، هشها (hashes) و موارد دیگر پشتیبانی میکند. در مقابل، پایگاههای داده سنتی معمولاً طرحوارههای ساختاریافته دارند و از SQL یا سایر زبانهای کوئری پشتیبانی میکنند.
عملکرد
ردیس یک پایگاه داده در حافظه است، به این معنی که دادهها را برای دسترسی سریعتر در حافظه سرور ذخیره میکند. این طراحی به Redis اجازه می دهد تا به تاخیر بسیار کم و توان عملیاتی بالا در مقایسه با پایگاه دادههای مبتنی بر دیسک دست یابد. با این حال، این به آن معناست که دادههای Redis بهطور پیشفرض فرّار هستند (اگرچه در صورت نیاز میتوان آنها را روی دیسک نگه داشت). پایگاههای اطلاعاتی سنتی معمولاً بر روی ذخیرهسازی دائمی تمرکز میکنند، که میتواند کندتر باشد، اما دوام و ذخیرهسازی دادههای غیر فرّار را ارائه میدهد.
Use Case
ردیس اغلب به عنوان یک لایه کَش یا به عنوان یک راه حل ذخیره سازی موقت برای داده های متداول یا transient استفاده می شود. سرعت و سادگی آن، آن را برای اپلیکیشنهای real-time، مدیریت Session، حافظه پنهان، سیستمهای پیام رسانی و موارد دیگر مناسب میکند. از سوی دیگر، پایگاههای داده سنتی معمولاً برای ذخیرهسازی مداوم و مدیریت دادههای ساختیافته استفاده میشوند.
ویژگیها
Redis ویژگی های مختلفی را ارائه میدهد که معمولاً در پایگاه های داده سنتی یافت نمیشوند. این ویژگی ها عبارتند از انتشار/اشتراک پیام (publish/subscribe messaging)، انقضای داده، عملیات اتمی (atomic operations)، نمایه سازی مکانی (geospatial indexing)، اسکریپت نویسی Lua و غیره. پایگاه های داده سنتی اغلب بر روی ارائه قابلیت های گسترده کوئری، تراکنش های پیچیده و ویژگی های یکپارچگی دادهها تمرکز میکنند.
مقیاس پذیری
ردیس به دلیل توانایی خود در مقیاس افقی با استفاده از تکنیک های خوشه بندی (clustering) و تقسیم بندی (sharding) شناخته شده است. ردیس میتواند دادهها را در چندین نمونه توزیع کند، که امکان افزایش توان و ظرفیت را فراهم میکند. پایگاه دادههای سنتی ممکن است محدودیتهای مقیاسپذیری داشته باشند و اغلب به تنظیمات و پیکربندی اضافی برای محیطهای توزیع شده نیاز دارند.
**به خاطر داشته باشید که Redis، به عنوان یک پایگاه داده درون حافظه، دارای معاوضههای خاصی در مقایسه با پایگاه دادههای سنتی مبتنی بر دیسک است. در سناریوهایی که نیاز به ذخیرهسازی داده با کارایی بالا، تأخیر کم، ذخیرهسازی و پردازش داده به صورت ریل تایم دارند، عالی است، اما ممکن است برای سناریوهایی که دوام دقیق (strict durability) یا جستجوی (کوئری) پیچیده برای آنها در اولویت است، انتخاب ایدهآلی نباشد.
مزایای Redis
- سازگاری با اغلب زبانهای برنامهنویسی
- ذخیره سازی In-Memory Database
- سیستم تکثیر master-slave replication
- کاهش هزینهها
- سرعت بالا
- ساختارهای داده متنوع و انعطاف پذیر (پیشتر درباره انواع دادههایی که ردیس از آنها پشتیبانی میکند صحبت کردیم.)
- محبوبیت بین دِوِلوپرها به دلیل ساختاری مشابه دیتابیس NoSQL
- کاهش هزینهها به دلیل مصرف منابع کمتر در سرور و نیاز به زیرساخت کمتر
- پشتیبانی از زبانهای برنامهنویسی مختلف
- عملکرد عالی و استفاده آسان
- افزایش سرعت پلتفرمهای پخش ویدئو
- مجهز به ماژولهای مختلف
- ماندگاری بالای دادهها
برجستهترین موارد استفاده ردیس
- اپلیکیشنهای موقعیت-محور (اپلیکیشنهایی که به تشخیص موقعیت مکانی نیاز دارند.) مانند سایتهای رزور هتل، بلیت هواپیما و …
- تکثیر دادهها
- طراحی وبسایت فروشگاهی و پلتفرمهای
- تجزیه و تحلیل زمان واقعی (Real-time)
- اپلیکیشنهای پیامرسانی و مبتنی بر IoT
- ذخیره سازی
- سایتهای خبری و بازیهای آنلاین
- سایتهای استاتیک و دینامیک (بخوانید: تفاوت سایت داینامیک و استاتیک)
- سایتهای پخش ویدئو
- موتورهای جستجو
- فرومها و پلتفرمهای آموزش آنلاین
-
محسن
18 مرداد 1403خیلی مختصر و مفید بود. ممنون از خانم صادقی
-
محدثه
11 دی 1403سلام واقعا مفید بود. ممنون


.svg)
